To answer, in order:
1
USB issues interfering with your connection is not a known problem. You were the first to report it, and I was unable to reproduce it here. If it works, I indeed would recommend disconnecting them, as they’re not required anyway.
2
Yes, It can be. IPv6 is of limited importance in a local network anyway, so normally we recommend running brewblox-ctl disable-ipv6. Even if it doesn’t solve the problem, it won’t hurt.
3
Docker images are like a .exe file. You start them to run the software, but they do not contain your brew data.
Downloading an updated image does not remove the old one. To reclaim disk space, we can clean up these backups of old images. This is a system-wide cleanup, so we ask first. The user may have non-brewblox images he doesn’t want cleaned up.
This is a case of “if you have to ask, always choose yes”.
4
Logged data is stored on the Pi, but nothing is secret, and there are alternatives to using the Brewblox UI. You could set up chronograf or even query the raw data. I posted instructions on how to do this some time ago, but would have to look up the topic.
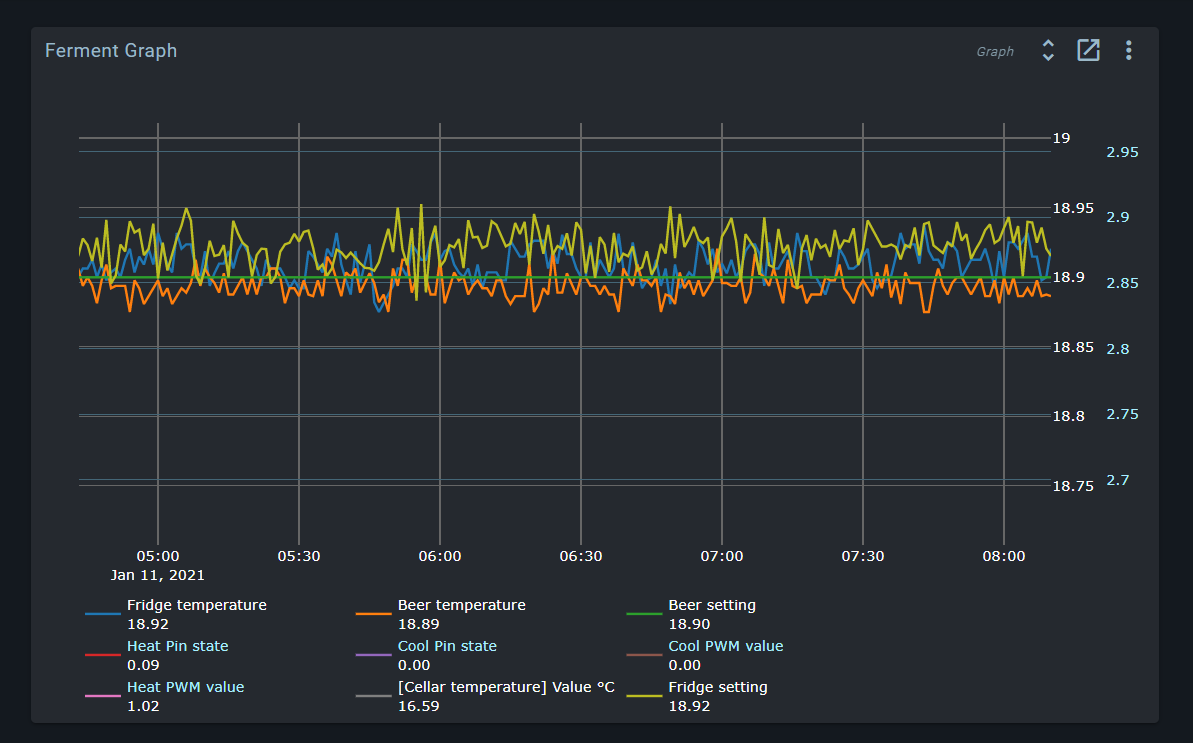
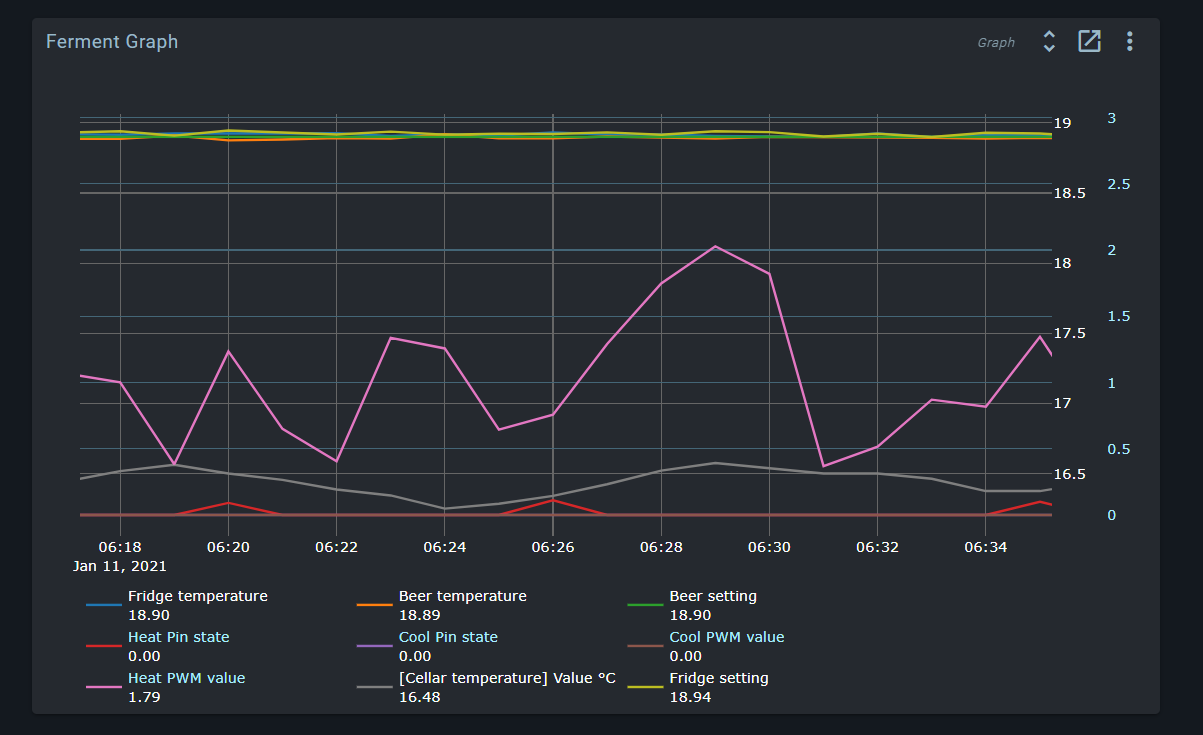
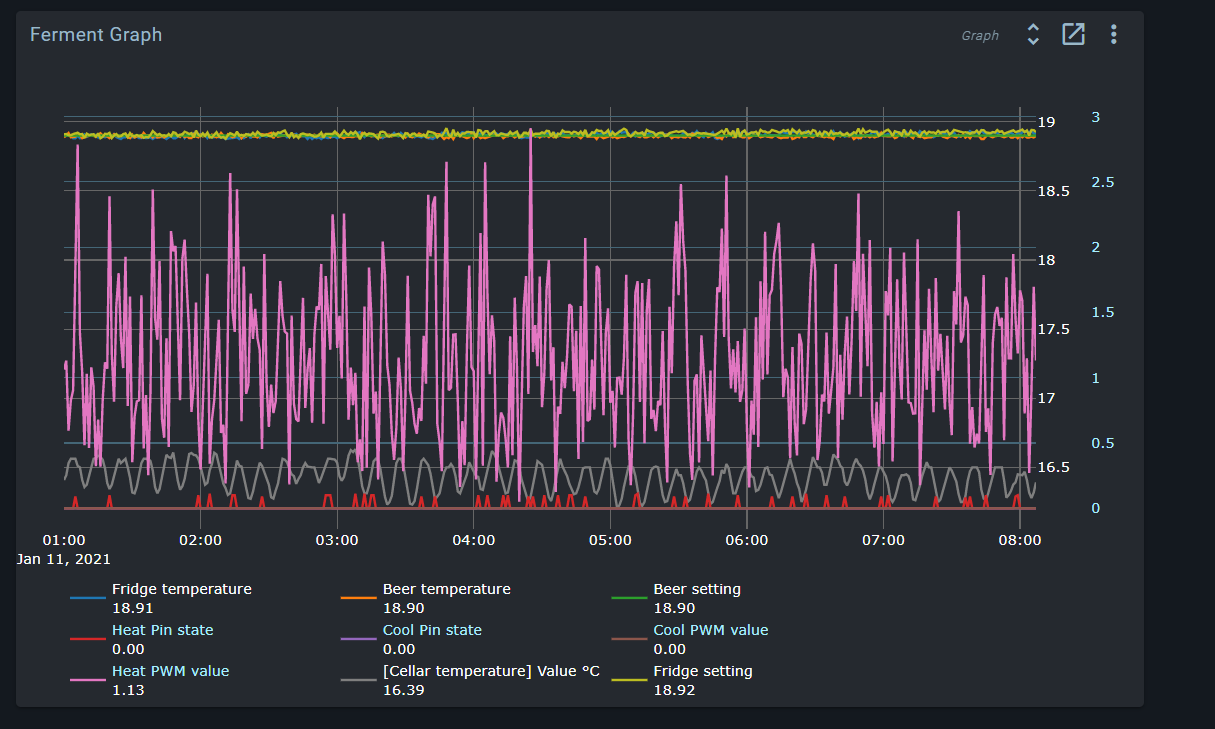
Raw sample rate for the Spark service is 5s, but this dataset is only kept for 24h.
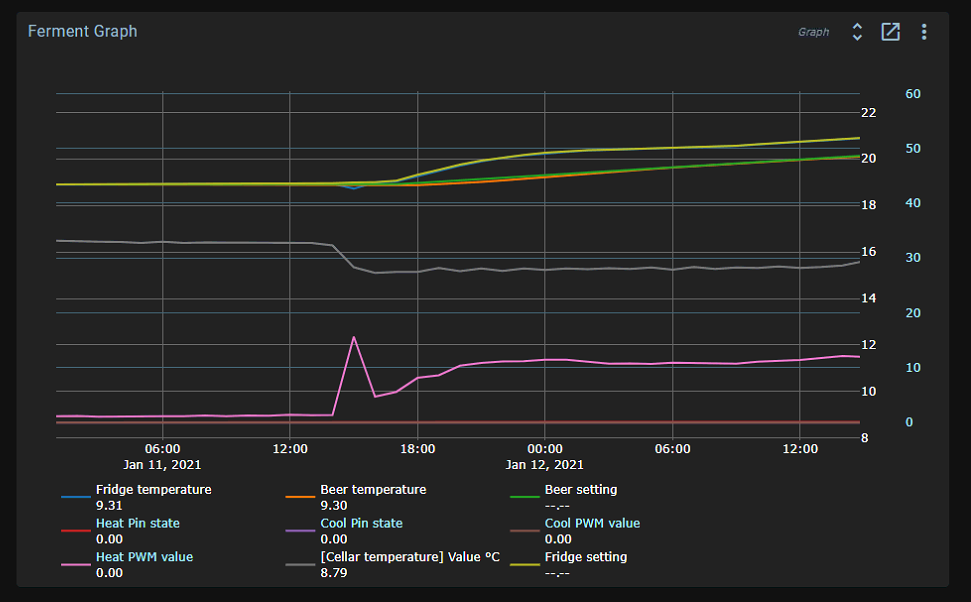
Beyond this, we progressively downsample averaged values to multiple concurrent datasets (1m, 10m, 1h, 6h). These datasets are kept indefinitely.
When viewing a graph in the UI, the most appropriate dataset is selected based on available data. If you set the graph to show the last 10m, you’ll get realtime (5s) data, but if you show the last month, you’ll get data from either the 1h or the 6h dataset. If you select a 10m period from last week, you’ll get data from the 1m dataset.
CSV exports always use the 1m dataset because this is the highest resolution that is kept indefinitely.